
[Spring][JPA] 자바 ORM 표준 JPA
들어가며
해당 게시글은 인프런 김영한 강사님의 자바 ORM 표준 JPA 프로그래밍 - 기본편 강의와 도서를 바탕으로 쓰였음을 미리 밝힙니다.
JPA 소개
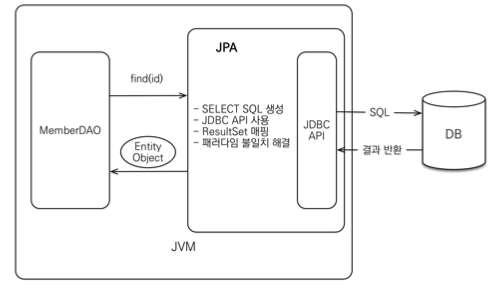
SQL 중심적인 개발의 문제점
- 객체 지향 언어
- 관계형 데이터베이스
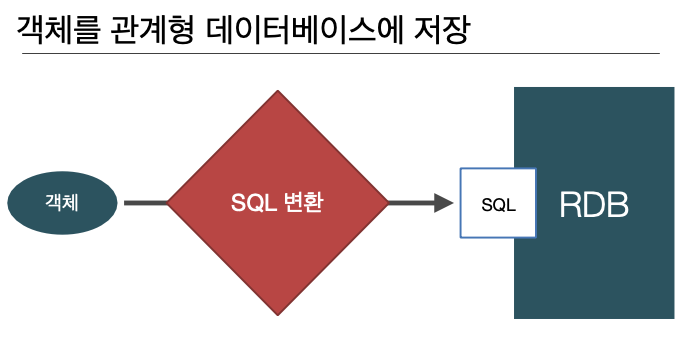
- 객체를 관계형 데이터베이스에 관리
- CRUD(객체를 SQL로, SQL을 자바 객체로)
public class Member {
private String memberId;
private String name;
...
}
INSERT INTO MEMBER(MEMBER_ID, NAME) VALUES
SELECT MEMBER_ID, NAME FROM MEMBER M
UPDATE MEMBER SET ...
- 필드 수정시 SQL을 모두 수정해야함.
- 패러다임의 불일치(객체 vs 관계형 데이터베이스)
- 객체와 관계형 데이터베이스의 차이
- 상속
- 연관관계
- 데이터 타입
- 데이터 식별 방법
- 상속
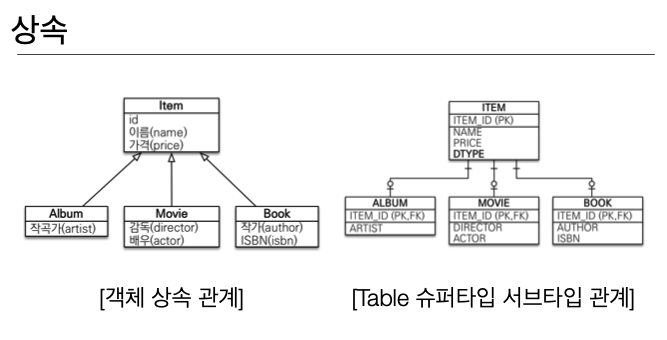
- INSERT 쿼리를 두 번 생성해야 한다.
-
각각의 테이블에 따른 조인 SQL 작성
- 연관관계
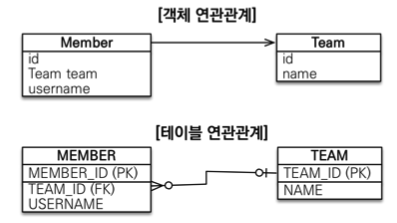
- 객체는 참조를 사용:
member.getTeam() - 테이블은 외래 키를 사용:
JOIN ON M.TEAM_ID = T.TEAM_ID - 객체를 테이블에 맞추어 모델링 하는 경우 객체 지향 언어의 장점이 사라진다.
- 객체 모델링 저장을 하는 경우 조회시에 모든 데이터를 끌고 와서 객체를 생성한 후 참조관계를 설정해주어야 한다.
- 객체 그래프 탐색시 처음 실행하는 SQL에 따라 탐색 범위가 결정된다.

–> 객체답게 모델링 할수록 매핑 작업만 늘어난다.
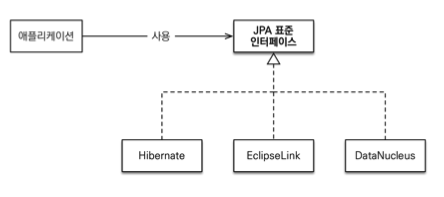
JPA(Java Persistence API) 소개
- 자바 진영의 ORM 기술 표준
- Object-relational mapping(객체 관계 매핑)
- 객체는 객체대로 설계
- 관계형 데이터베이스는 관계형 데이터베이스대로 설계
- ORM 프레임워크가 중간에서 매핑
- JPA는 애플리케이션과 JDBC 사이에서 동작
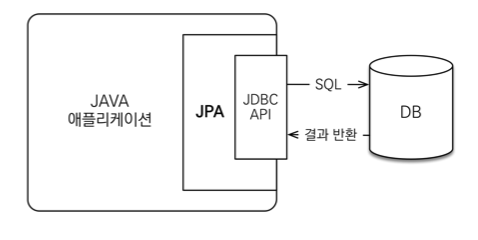

- JPA는 표준 명세
- JPA를 왜 사용해야 하는가?
- SQL 중심적인 개발에서 객체 중심으로 개발
- 생산성
- 유지보수
- 패러다임의 불일치 해결
- 생산성 - JPA와 CRUD
- 저장:
jpa.persist(member) - 조회:
Member member = jpa.find(memberId) - 수정:
member.setName(“변경할 이름”) - 삭제:
jpa.remove(member)
- 저장:
- 유지보수(기존: 필드 변경시 모든 SQL 수정)
- JPA 사용시 필드만 추가하면 됨
- JPA와 패러다임의 불일치 해결
- JPA와 상속: 여러 개의 INSERT 쿼리 자동생성, 여러 개의 테이블을 조인해서 SELECT 쿼리 자동생성
- JPA와 연관관계, 객체 그래프 탐색: 서로 다른 두 객체를 연관관계 설정시 적절한 INSERT SELECT 쿼리 자동생성
- JPA와 비교하기: 동일한 트랜잭션에서 조회한 엔티티는 같음을 보장(== 동등성 비교) - JPA의 성능 최적화 기능 - 1차 캐시와 동일성(identity) 보장 - 트랜잭션을 지원하는 쓰기 지연(transactional write-behind) - 지연 로딩(Lazy Loading)
- 1차 캐시와 동일성 보장: 같은 트랜잭션 안에서는 같은 엔티티를 반환(약간의 조회 성능 향상)
- 트랜잭션을 지원하는 쓰기 지연(INSERT): 트랜잭션을 커밋할 때까지 INSERT SQL을 모음, JDBC BATCH SQL 기능을 사용해서 한번에 SQL 전송
- 트랜잭션을 지원하는 쓰기 지연(UPDATE): UPDATE, DELETE로 인한 로우(ROW)락 시간 최소화, 트랜잭션 커밋 시 UPDATE, DELETE SQL 실행하고, 바로 커밋
- 지연 로딩과 즉시 로딩
- 지연로딩:객체가 실제 사용될 때 로딩
- 즉시 로딩: JOIN SQL로 한번에 연관된 객체까지 미리 조회
JPA 시작하기(애플리케이션 개발)
JPA 구동 방식
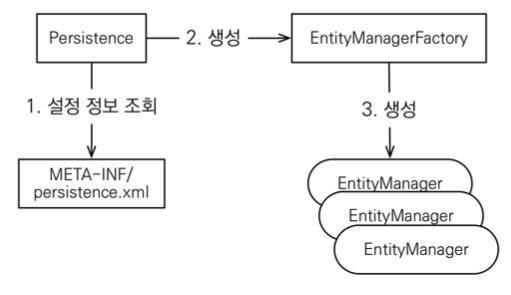
- 엔티티 매니저 팩토리는 하나만 생성해서 애플리케이션 전체에서 공유
- 엔티티 매니저는 쓰레드간에 공유X (사용하고 버려야 한다).
- JPA의 모든 데이터 변경은 트랜잭션 안에서 실행
JPQL
- 애플리케이션이 필요한 데이터만 DB에서 불러오려면 결국 검색 조건이 포함된 SQL이 필요
- JPA는 SQL을 추상화한 JPQL이라는 객체 지향 쿼리 언어 제공
- JPQL은 엔티티 객체를 대상으로 쿼리
- SQL은 데이터베이스 테이블을 대상으로 쿼리
- SQL을 추상화해서 특정 데이터베이스 SQL에 의존X
- JPQL을 한마디로 정의하면 객체 지향 SQL
영속성 관리 - 내부 동작 방식
영속성 컨텍스트 1
- 엔티티 매니저 팩토리와 엔티티 매니저
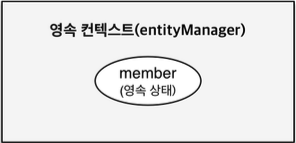
- 영속성 컨텍스트는 논리적인 개념(눈에 보이지 않음)
- 엔티티 매니저를 통해서 영속성 컨텍스트에 접근
- 엔티티의 생명주기
- 비영속 (new/transient): 영속성 컨텍스트와 전혀 관계가 없는 새로운 상태
- 영속 (managed): 영속성 컨텍스트에 관리되는 상태
- 준영속 (detached): 영속성 컨텍스트에 저장되었다가 분리된 상태
- 삭제 (removed): 삭제된 상태
- 영속
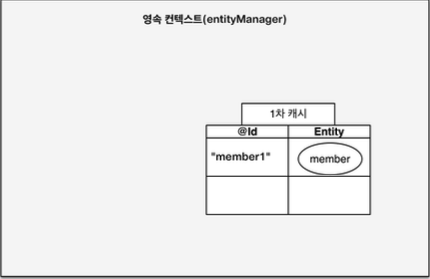
//객체를 생성한 상태(비영속)
Member member = new Member();
member.setId("member1");
member.setUsername(“회원1”);
EntityManager em = emf.createEntityManager();
em.getTransaction().begin();
//객체를 저장한 상태(영속)
em.persist(member);
- 준영속, 삭제
//회원 엔티티를 영속성 컨텍스트에서 분리, 준영속 상태
em.detach(member);
//객체를 삭제한 상태(삭제)
em.remove(member);
영속성 컨텍스트 2
- 엔티티 조회, 1차 캐시에서 조회(1차 캐시에 없는 경우 쿼리 생성)
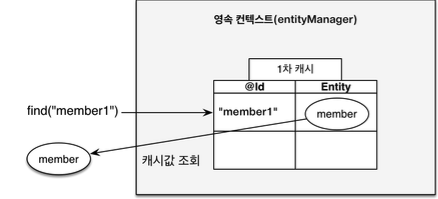
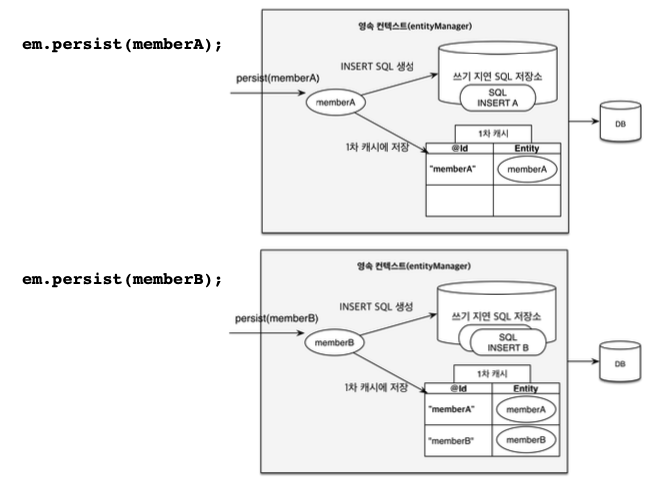
- 1차 캐시로 반복 가능한 읽기(REPEATABLE READ) 등급의 트랜잭션 격리 수준을 데이터베이스가 아닌 애플리케이션 차원에서 제공
- 트랜잭션을 지원하는 쓰기 지연
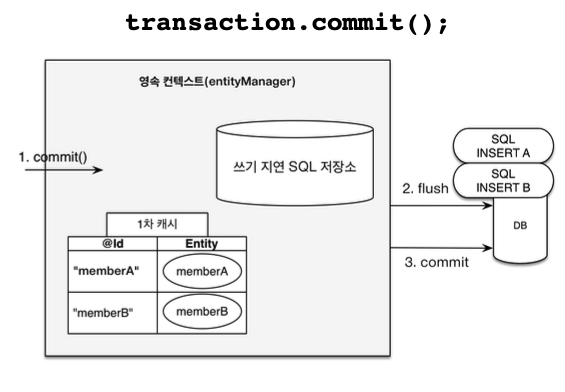
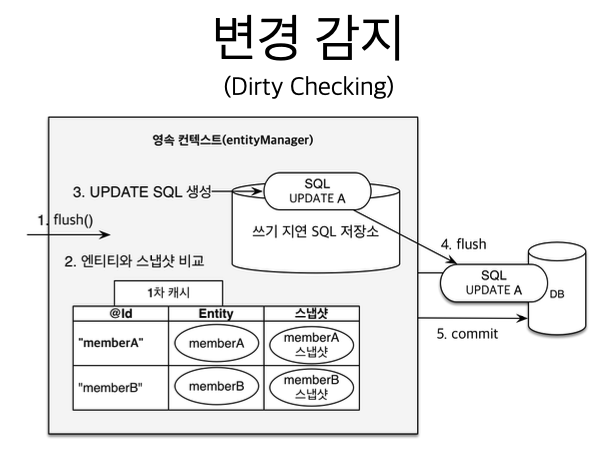
- 엔티티 수정(변경 감지)
// 영속 엔티티 조회
Member memberA = em.find(Member.class, "memberA");
// 영속 엔티티 데이터 수정
memberA.setUsername("hi");
memberA.setAge(10);
//em.update(member) 이런 코드가 있어야 하지 않을까?
transaction.commit(); // [트랜잭션] 커밋
- flush 시점에 영속성 컨텍스트 내에서 스냅샷과 Entity를 비교하여 UPDATE 쿼리를 생성한 후에 함께 flush 한다. 이후 commit를 한다.
- 플러시: 영속성 컨텍스트의 변경내용을 데이터베이스에 반영(1차 캐시 내용이 없어지는 것은 아니고 단지 컨텍스트와 데이터베이스 동기화 작업이라고 보면됨)
- 플러시 발생
- 변경 감지
- 수정된 엔티티를 쓰기 지연 SQL 저장소에 등록
- 쓰기 지연 SQL 저장소의 쿼리를 데이터베이스에 전송(등록, 수정, 삭제 쿼리)
- 플러시 방법
em.flush()- 직접 호출- 트랜잭션 커밋 - 플러시 자동 호출
- JPQL 쿼리 실행 - 플러시 자동 호출
- JPQL 쿼리 실행시 플러시가 자동으로 호출되는 이유: JPQL, 즉 SQL를 데이터베이스에 날려 원하는 결과를 얻기 위해서는 영속성 컨텍스트와 데이터베이스가 동기화 되어있어야 한다.
em.persist(memberA);
em.persist(memberB);
em.persist(memberC);
//중간에 JPQL 실행
query =em.createQuery("select m from Member m",Member .class);
List<Member> members = query.getResultList();
- 준영속 상태
- 영속 상태의 엔티티가 영속성 컨텍스트에서 분리(detached)
- 영속성 컨텍스트가 제공하는 기능을 사용 못함
- 준영속 상태로 만드는 방법
em.detach(entity): 특정 엔티티만 준영속 상태로 전환em.clear(): 영속성 컨텍스트를 완전히 초기화em.close(): 영속성 컨텍스트를 종료
엔티티 매핑
객체와 테이블 매핑
- 엔티티 매핑 소개
- 객체와 테이블 매핑:
@Entity,@Table - 필드와 컬럼 매핑:
@Column - 기본 키 매핑:
@Id - 연관관계 매핑:
@ManyToOne,@JoinColumn(외래키를 매핑할때 사용한다.)
- 객체와 테이블 매핑:
- 객체와 테이블 매핑
@Entity:@Entity가 붙은 클래스는 JPA가 관리, 엔티티라 한다.- 기본 생성자 필수(파라미터가 없는
public또는protected생성자) - 저장할 필드에
final사용 X final클래스,enum,interface,inner클래스 사용X
- 기본 생성자 필수(파라미터가 없는
@Entity속성 정리name: JPA에서 사용할 엔티티 이름을 지정한다. 기본값: 클래스 이름을 그대로 사용(예: Member). 같은 클래스 이름이 없으면 가급적 기본값을 사용한다.@Table
| 속성 | 기능 | 기본값 |
|---|---|---|
| name | 매핑할 테이블 이름 | 엔티티 이름을 사용 |
| catalog | 데이터베이스 catalog 매핑 | |
| schema | 데이터베이스 schema 매핑 | |
| uniqueConstraints (DDL) | DDL 생성 시에 유니크 제약 조건 생성 |
데이터베이스 스키마 자동 생성
- DDL을 애플리케이션 실행 시점에 자동 생성
- 테이블중심 -> 객체중심
- 데이터베이스 방언을 활용해서 데이터베이스에 맞는 적절한 DDL 생성
- 이렇게 생성된 DDL은 개발 장비에서만 사용
- 생성된 DDL은 운영서버에서는 사용하지 않거나, 적절히 다듬은 후 사용
- 데이터베이스 스키마 자동 생성 - 속성
| 옵션 | 설명 |
|---|---|
| create | 기존테이블 삭제 후 다시 생성 (DROP + CREATE) |
| create-drop | create와 같으나 종료시점에 테이블 DROP |
| update | 변경분만 반영(운영DB에는 사용하면 안됨) |
| validate | 엔티티와 테이블이 정상 매핑되었는지만 확인 |
| none | 사용하지 않음 |
- 데이터베이스 스키마 자동 생성 - 주의
- 운영 장비에는 절대 create, create-drop, update 사용하면 안된다.
- 개발 초기 단계는 create 또는 update
- 테스트 서버는 update 또는 validate
- 스테이징과 운영 서버는 validate 또는 none
- DDL 생성 기능
- 제약조건 추가: 회원 이름은 필수, 10자 초과X ->
@Column(nullable = false, length = 10) - 유니크 제약조건 추가 ->
@Table(uniqueConstraints = {@UniqueConstraint( name = "NAME_AGE_UNIQUE", columnNames = {"NAME", "AGE"})})
- 제약조건 추가: 회원 이름은 필수, 10자 초과X ->
필드와 컬럼 매핑
@Entity
public class Member {
@Id
private Long id;
@Column(name = "name")
private String username;
private Integer age;
@Enumerated(EnumType.STRING)
private RoleType roleType;
@Temporal(TemporalType.TIMESTAMP)
private Date createdDate;
@Temporal(TemporalType.TIMESTAMP)
private Date lastModifiedDate;
@Lob
private String description;
//Getter, Setter
}
| 어노테이션 | 설명 |
|---|---|
| @Column | 컬럼 매핑 |
| @Temporal | 날짜 타입 매핑 |
| @Enumerated | enum 타입 매핑 |
| @Lob | BLOB, CLOB 매핑 |
| @Transient | 특정 필드를 컬럼에 매핑하지 않음(매핑 무시) |
- @Column
| 속성 | 설명 | 기본값 |
|---|---|---|
| name | 필드와 매핑할 테이블의 컬럼 이름 | 객체의 필드 이름 |
| insertable, updatable | 등록, 변경 가능 여부 | TRUE |
| nullable(DDL) | null 값의 허용 여부를 설정한다. false로 설정하면 DDL 생성 시에 not null 제약조건이 붙는다. | |
| unique(DDL) | @Table의 uniqueConstraints와 같지만 한 컬럼에 간단히 유니크 제약조건을 걸 때 사용한다. | |
| columnDefinition (DDL) | 데이터베이스 컬럼 정보를 직접 줄 수 있다. ex) varchar(100) default ‘EMPTY’ | 필드의 자바 타입과 방언 정보를 사용해 |
| length(DDL) | 문자 길이 제약조건, String 타입에만 사용한다. | 255 |
| precision, scale(DDL) | BigDecimal 타입에서 사용한다(BigInteger도 사용할 수 있다). precision은 소수점을 포함한 전체 자릿수를, scale은 소수의 자릿수 다. 참고로 double, float 타입에는 적용되지 않는다. 아주 큰 숫자나 정밀한 소수를 다루어야 할 때만 사용한다. | precision=19, scale=2 |
@Enumerated: 자바 enum 타입을 매핑할 때 사용(EnumType.STRING사용권장)@Temporal:LocalDate,LocalDateTime을 사용할 때는 생략 가능(최신 하이버네이트 지원)@Lob:@Lob에는 지정할 수 있는 속성이 없다. 매핑하는 필드 타입이 문자면CLOB매핑, 나머지는BLOB매핑
기본 키 매핑
- 기본 키 매핑 어노테이션:
@Id,@GeneratedValue
@Id @GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
- 기본 키 매핑 방법
- 직접 할당:
@Id만 사용 - 자동 생성(
@GeneratedValue)IDENTITY: 데이터베이스에 위임, MYSQLSEQUENCE: 데이터베이스 시퀀스 오브젝트 사용, ORACLE(@SequenceGenerator필요)TABLE: 키 생성용 테이블 사용, 모든 DB에서 사용(@TableGenerator필요)AUTO: 방언에 따라 자동 지정, 기본값
- 직접 할당:
- IDENTITY 전략 - 특징
- 기본 키 생성을 데이터베이스에 위임
- 주로 MySQL, PostgreSQL, SQL Server, DB2에서 사용(예: MySQL의
AUTO_ INCREMENT) - JPA는 보통 트랜잭션 커밋 시점에 INSERT SQL 실행
AUTO_ INCREMENT는 데이터베이스에 INSERT SQL을 실행한 이후에 ID 값을 알 수 있음IDENTITY전략은em.persist()시점에 즉시 INSERT SQL 실행하고 DB에서 식별자를 조회
- SEQUENCE 전략 - 특징
- 데이터베이스 시퀀스는 유일한 값을 순서대로 생성하는 특별한 데이터베이스 오브젝트(예: 오라클 시퀀스)
- 오라클, PostgreSQL, DB2, H2 데이터베이스에서 사용
@Entity
@SequenceGenerator(
name = "MEMBER_SEQ_GENERATOR",
sequenceName= "MEMBER_SEQ", //매핑할 데이터베이스 시퀀스 이름
initialValue= 1, allocationSize = 1)
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "MEMBER_SEQ_GENERATOR")
private Long id;
}
| 속성 | 설명 | 기본값 |
|---|---|---|
| name | 식별자 생성기 이름 | 필수 |
| sequenceName | 데이터베이스에 등록되어 있는 시퀀스 이름 | hibernate_sequence |
| initialValue | DDL 생성시에만 사용됨, 시퀀스 DDL을 생성할 때 처음 시작하는 수를 지정한다. | 1 |
| allocationSize | 시퀀스 한 번 호출에 증가하는 수(성능 최적화에 사용됨 데이터베이스 시퀀스 값이 하나씩 증가하도록 설정되어 있으면 이 값을 반드시 1로 설정해야 한다 | 50 |
| catalog, schema | 데이터베이스 catalog, schema 이름 |
- TABLE 전략
- 키 생성 전용 테이블을 하나 만들어서 데이터베이스 시퀀스를 흉내내는 전략
- 장점: 모든 데이터베이스에 적용 가능
- 단점: 성능
- 권장하는 식별자 전략
- 기본 키 제약 조건:
null아님, 유일, 변하면 안된다. - 미래까지 이 조건을 만족하는 자연키는 찾기 어렵다. 대리키(대체키)를 사용하자.
- 예를 들어 주민등록번호도 기본키로 적절하기 않다.
- 권장: Long형 + 대체키 + 키 생성전략 사용
- 기본 키 제약 조건:
연관관계 매핑 기초
연관관계가 필요한 이유
- 객체를 테이블에 맞추어 데이터 중심으로 모델링하면, 협력 관계를 만들 수 없다.
- 객체는 참조를 사용해서 연관된 객체를 찾는다.
단방향 연관관계
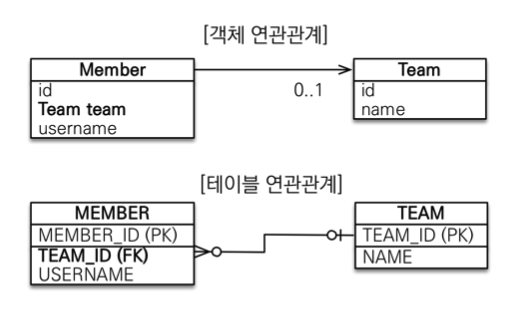
@Entity
public class Member {
@Id @GeneratedValue
private Long id;
@Column(name = "USERNAME")
private String name;
private int age;
// @Column(name = "TEAM_ID")
// private Long teamId;
@ManyToOne
@JoinColumn(name = "TEAM_ID")
private Team team;
}
양방향 연관관계와 연관관계의 주인1 - 기본
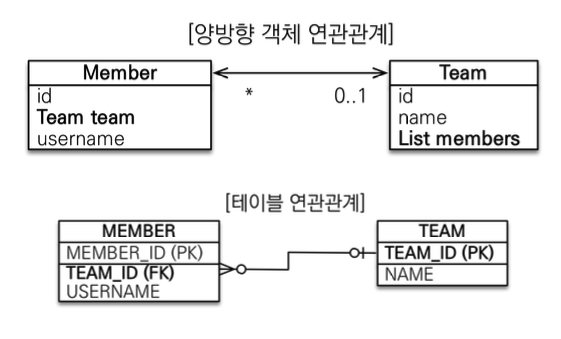
@Entity
public class Member {
private Long id;
@Column(name = "USERNAME")
private String name;
private int age;
@ManyToOne
@JoinColumn(name = "TEAM_ID")
private Team team;
}
@Entity
public class Team {
@Id
@GeneratedValue
private Long id;
private String name;
@OneToMany(mappedBy = "team")
List<Member> members = new ArrayList<Member>();
}
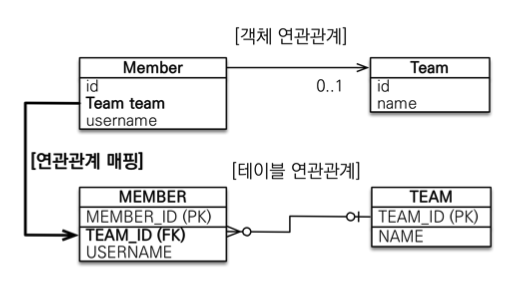
- 연관관계의 주인과
mappedBy: 객체와 테이블간에 연관관계를 맺는 차이를 이해해야 한다. - 객체와 테이블이 관계를 맺는 차이
- 객체 연관관계 = 2개: 회원 -> 팀 연관관계 1개(단방향) + 팀 -> 회원 연관관계 1개(단방향)
- 테이블 연관관계 = 1개: 회원 <-> 팀의 연관관계 1개(양방향)
- 객체의 양방향 관계는 사실 양방향 관계가 아니라 서로 다른 단뱡향 관계 2개다.
- 테이블은 외래키 하나로 두 테이블의 연관관계를 관리,
MEMBER.TEAM_ID외래키 하나로 양방향 연관관계 가짐 (양쪽으로 조인할 수 있다.)
SELECT *
FROM MEMBER M
JOIN TEAM T ON M.TEAM_ID = T.TEAM_ID
SELECT *
FROM TEAM T
JOIN MEMBER M ON T.TEAM_ID = M.TEAM_ID
- 둘 중 하나로 외래키를 관리해야 한다.
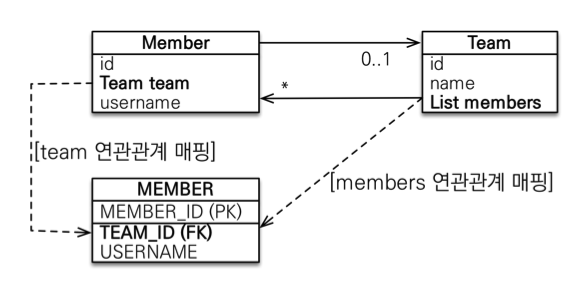
- 연관관계의 주인(Owner)
- 객체의 두 관계중 하나를 연관관계의 주인으로 지정
- 연관관계의 주인만이 외래키를 관리(등록, 수정)
- 주인이 아닌쪽은 읽기만 가능
- 주인은
mappedBy속성 사용X - 주인이 아니면
mappedBy속성으로 주인 지정
- 누구를 주인으로? -> 외래 키가 있는 있는 곳을 주인으로 정해라
- 양방향 매핑시 가장 많이 하는 실수
Team team = new Team();
team.setName("TeamA");
em.persist(team);
Member member = new Member();
member.setName("member1");
//역방향(주인이 아닌 방향)만 연관관계 설정
team.getMembers().add(member);
em.persist(member);

양방향 연관관계와 연관관계의 주인2 - 주의점
- 순수 객체 상태를 고려해서 항상 양쪽에 값을 설정하자
- 연관관계 설정 후 데이터베이스에서 객체를 가져오면 괜찮으나 1차 캐시에서 값을 가져오는 경우 NPE가 발생할 수 있다.
- 테스트 케이스 작성시 NPE 또는 빈 객체가 조회될 수도 있다.
- 연관관계 편의 메소드를 생성하자
- 양방향 매핑시에 무한 루프를 조심하자(
toString(), lombok, JSON 생성 라이브러리) - 양방향 매핑 정리
- 단방향 매핑만으로도 이미 연관관계 매핑은 완료
- 양방향 매핑은 반대 방향으로 조회(객체 그래프 탐색) 기능이 추가된 것 뿐
- JPQL에서 역방향으로 탐색할 일이 많음
- 단방향 매핑을 잘 하고 양방향은 필요할 때 추가해도 됨 (테이블에 영향을 주지 않음)
- 연관관계의 주인을 정하는 기준
- 비즈니스 로직을 기준으로 연관관계의 주인을 선택하면 안됨
- 연관관계의 주인은 외래키의 위치를 기준으로 정해야함
다양한 연관관계 매핑
연관관계 매핑시 고려사항 3가지
- 다중성(
@ManyToOne,@OneToMany,@OneToOne,@ManyToMany) - 단방향, 양방향
- 연관관계의 주인
다대일 [N:1]
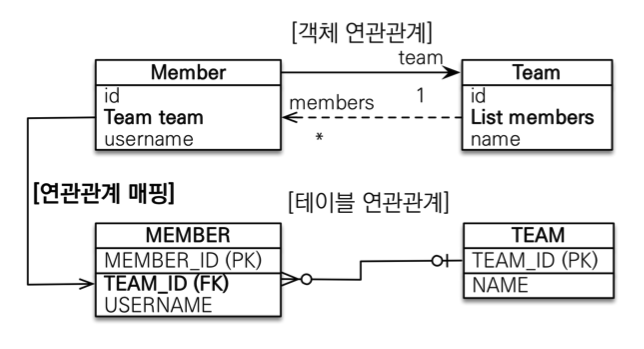
- 가장 많이 사용하는 연관관계
- 외래키가 있는 쪽이 연관관계의 주인
일대다 [1:N]
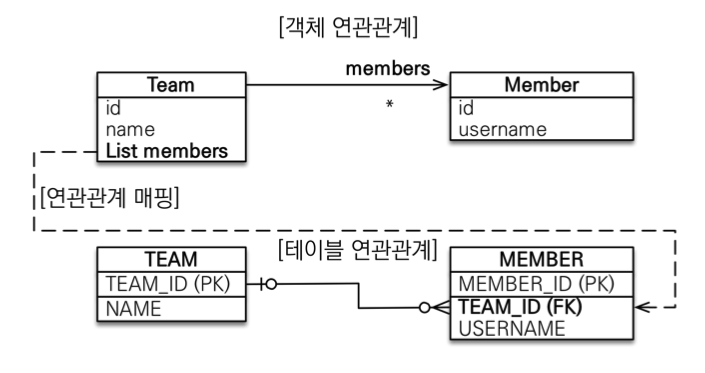
- 테이블 일대다 관계는 항상 다(N)쪽에 외래키가 있음
- 객체와 테이블의 차이 때문에 반대편 테이블의 외래키를 관리하는 특이한 구조
@JoinColumn을 꼭 사용해야 함. 그렇지 않으면 조인 테이블 방식을 사용함(중간에 테이블을 하나 추가함)- 일대다 단방향 매핑의 단점
- 엔티티가 관리하는 외래키가 다른 테이블에 있음
- 연관관계 관리를 위해 추가로 외래키와 관련하여 UPDATE SQL 실행
- 일대다 양방향의 경우 공식적인 표준스펙은 아니며 권장하지 않는다.
일대일 [1:1]
- 일대일 관계는 그 반대도 일대일
- 주테이블이나 대상테이블 중에 외래키 선택 가능
- 외래 키에 데이터베이스 유니크(UNI) 제약조건 추가
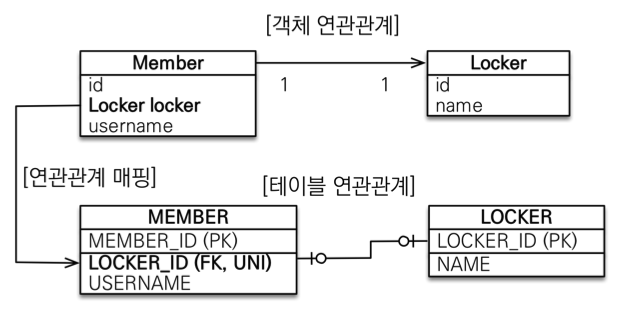
- 주테이블에 외래키
- 주 객체가 대상 객체의 참조를 가지는 것처럼 주 테이블에 외래키를 두고 대상 테이블을 찾음
- 객체지향 개발자 선호
- JPA 매핑 편리(주테이블이므로 단방향 연관관계만 설정)
- 장점: 주 테이블만 조회해도 대상 테이블에 데이터가 있는지 확인 가능
- 단점: 값이 없으면 외래 키에
null허용
- 대상테이블에 외래키
- 대상 테이블에 외래 키가 존재
- 전통적인 데이터베이스 개발자 선호
- 장점: 주 테이블과 대상 테이블을 일대일에서 일대다 관계로 변경할 때 테이블 구조 유지
- 단점: 프록시 기능의 한계로 지연 로딩으로 설정해도 항상 즉시 로딩됨 -> 대상테이블에 외래키가 존재하는 경우 주객체를 로딩할때 대상객체가 존재하는지 아닌지를 주테이블 만으로는 알수가 없기에 어차피 JOIN 쿼리가 나가게 된다.
- 단점: 대상테이블에 외래키가 있으므로 양방향 연관관계 설정 필요
다대다 [N:M]
- 관계형 데이터베이스는 정규화된 테이블 2개로 다대다 관계를 표현할 수 없음
- 연결 테이블을 추가해서 일대다, 다대일 관계로 풀어내야함
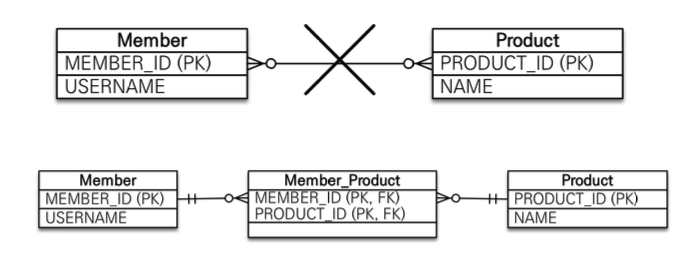
- 다대다 매핑의 한계
- 편리해 보이지만 실무에서 사용X
- 연결 테이블이 단순히 연결만 하고 끝나지 않음
- 주문시간, 수량 같은 데이터가 들어올 수 있음
- 다대다 한계 극복
- 연결 테이블용 엔티티 추가(연결 테이블을 엔티티로 승격)
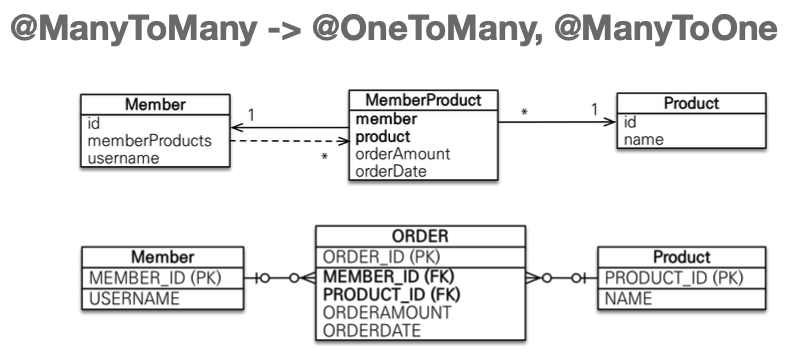
고급 매핑
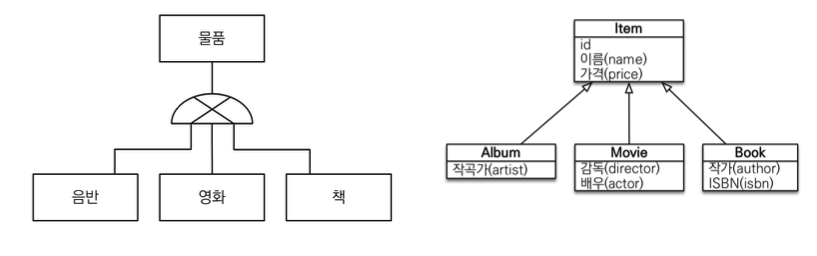
상속관계 매핑
- 관계형 데이터베이스는 상속 관계X
- 슈퍼타입 서브타입 관계라는 모델링 기법이 객체 상속과 유사
- 상속관계 매핑: 객체의 상속과 구조와 DB의 슈퍼타입 서브타입 관계를 매핑
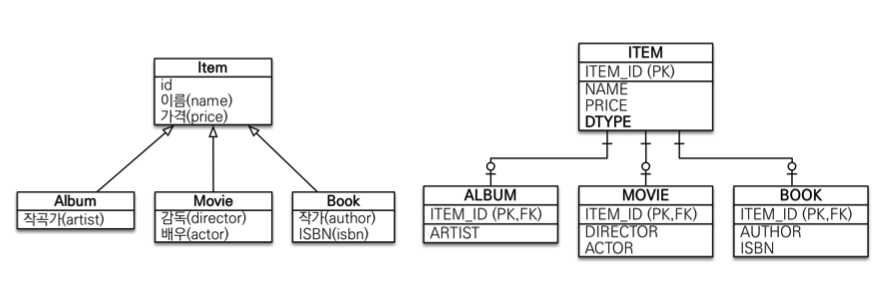
- 각각 테이블로 변환 -> 조인전략(
JOINED)- 테이블 정규화
- 외래 키 참조 무결성 제약조건 활용가능
- 저장공간 효율화
- 조회시 조인을 많이 사용, 성능저하
- 데이터 저장시 INSERT SQL 2번 호출
- 통합 테이블로 변환 -> 단일 테이블 전략(
SINGLE_TABLE)- 조인이 필요 없으므로 일반적으로 조회 성능이 빠름
- 조회 쿼리가 단순함
- 자식 엔티티가 매핑한 컬럼은 모두
null허용 - 단일 테이블에 모든 것을 저장하므로 테이블이 커질 수 있다. 상황에 따라서 조회 성능이 오히려 느려질 수 있다.
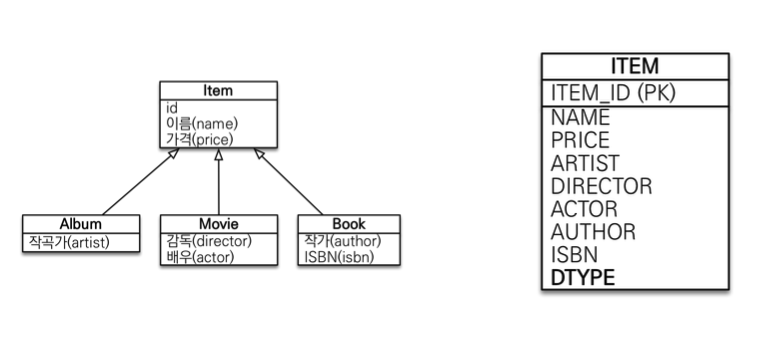
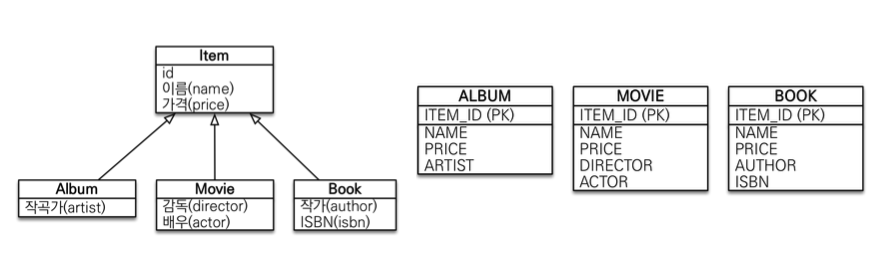
- 서브타입 테이블로 변환 -> 구현 클래스마다 테이블 전략(
TABLE_PER_CLASS)- 이 전략은 데이터베이스 설계자와 ORM 전문가 둘 다 추천X
- 여러 자식 테이블을 함께 조회할 때 성능이 느림(UNION SQL 필요)
- 자식 테이블을 통합해서 쿼리하기 어려움
- 주요 어노테이션
@Inheritance(strategy=InheritanceType.XXX)@DiscriminatorColumn(name=“DTYPE”)@DiscriminatorValue(“XXX”)
@MappedSuperclass - 매핑 정보 상속
- 공통 매핑 정보가 필요할 때 사용(id, name)
- 상속관계 매핑X
- 엔티티X, 테이블과 매핑X
- 부모 클래스를 상속 받는 자식 클래스에 매핑 정보만 제공
- 조회, 검색 불가(
em.find(BaseEntity) 불가) - 직접 생성해서 사용할 일이 없으므로 추상 클래스 권장
@MappedSuperclass- 테이블과 관계 없고, 단순히 엔티티가 공통으로 사용하는 매핑 정보를 모으는 역할
- 주로 등록일, 수정일, 등록자, 수정자 같은 전체 엔티티에서 공통으로 적용하는 정보를 모을 때 사용
@Entity클래스는 엔티티나@MappedSuperclass로 지정한 클래스만 상속 가능
프록시와 연관관계 관리
프록시
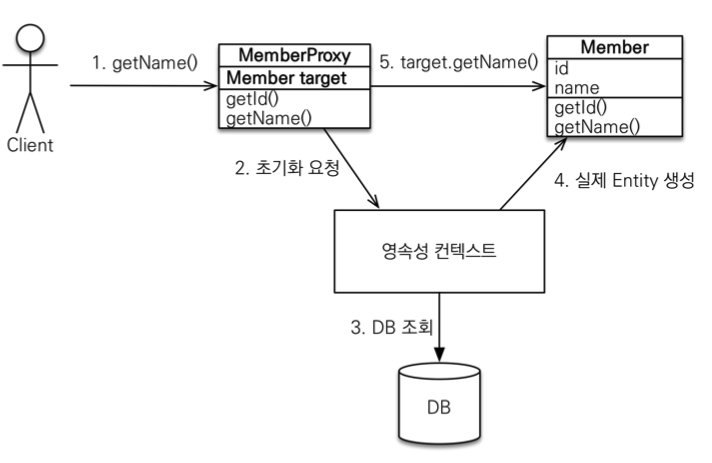
em.find()vsem.getReference()em.find(): 데이터베이스를 통해서 실제 엔티티 객체 조회em.getReference(): 데이터베이스 조회를 미루는 가짜(프록시) 엔티티 객체 조회
- 프록시 특징
- 실제 클래스를 상속 받아서 만들어짐
- 실제 클래스와 겉모양이 같다.
- 사용하는 입장에서는 진짜 객체인지 프록시 객체인지 구분하지 않고 사용하면 됨(이론상)
- 프록시 객체는 실제 객체의 참조(target)를 보관
- 프록시 객체를 호출하면 프록시 객체는 실제 객체의 메소드 호출
- 프록시 객체는 처음 사용할때 한 번만 초기화
- 초기화되면 프록시 객체를 통해서 실제 엔티티에 접근 가능
- 프록시 객체는 원본 엔티티를 상속받음, 따라서 타입 체크시 주의해야함 (== 비교 실패, 대신 instance of 사용)
- 영속성 컨텍스트에 찾는 엔티티가 이미 있으면
em.getReference()를 호출해도 실제 엔티티 반환 - 영속성 컨텍스트의 도움을 받을 수 없는 준영속 상태일 때, 프록시를 초기화하면 문제 발생(하이버네이트는 org.hibernate.LazyInitializationException 예외를 터트림)
즉시 로딩과 지연 로딩
- 엔티티 참고관계에서 참조하는 객체의 필드값을 이용할 때까지 프록시 객체로 지연로딩을 구현(사용하는 시점에 쿼리가 나감)
@Entity
public class Member {
@Id @GeneratedValue
private Long id;
@Column(name = "USERNAME")
private String name;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "TEAM_ID")
private Team team;
}
- 프록시와 즉시로딩 주의
- 가급적 지연 로딩만 사용(특히 실무에서)
- 즉시 로딩을 적용하면 예상하지 못한 SQL이 발생
- 즉시 로딩은 JPQL에서 N+1 문제를 일으킨다.
@ManyToOne,@OneToOne은기본이 즉시 로딩 ->LAZY로 설정@OneToMany,@ManyToMany는 기본이 지연 로딩
영속성 전이: CASCADE
- 특정 엔티티를 영속 상태로 만들 때 연관된 엔티티도 함께 영속 상태로 만들도 싶을 때
- 엔티티를 영속화할 때 연관된 엔티티도 함께 영속화하는 편리함을 제공할 뿐
ALL: 모두 적용PERSIST: 영속REMOVE: 삭제
고아 객체
- 고아 객체 제거: 부모 엔티티와 연관관계가 끊어진 자식 엔티티를 자동으로 삭제
orphanRemoval = true- 참조가 제거된 엔티티는 다른 곳에서 참조하지 않는 고아 객체로 보고 삭제하는 기능
- 참조하는 곳이 하나일 때 사용해야함!
@OneToOne,@OneToMany만 가능- 개념적으로 부모를 제거하면 자식은 고아가 된다. 따라서 고아 객체 제거 기능을 활성화 하면, 부모를 제거할 때 자식도 함께 제거된다. 이것은
CascadeType.REMOVE처럼 동작한다. - 영속성 전이 + 고아 객체, 생명주기(
CascadeType.ALL + orphanRemovel=true)- 스스로 생명주기를 관리하는 엔티티는
em.persist()로 영속화,em.remove()로 제거 - 두 옵션을 모두 활성화하면 부모 엔티티를 통해서 자식의 생명 주기를 관리할 수 있음
- 도메인 주도 설계(DDD)의 Aggregate Root개념을 구현할 때 유용
- 스스로 생명주기를 관리하는 엔티티는
값 타입
기본값 타입
- 엔티티 타입
@Entity로 정의하는 객체- 데이터가 변해도 식별자로 지속해서 추적 가능
- 예)회원 엔티티의 키나 나이값을 변경해도 식별자로 인식 가능
- 값 타입
- int, Integer, String처럼 단순히 값으로 사용하는 자바 기본 타입이나 객체
- 식별자가 없고 값만 있으므로 변경시 추적 불가
- 예) 숫자 100을 200으로 변경하면 완전히 다른 값으로 대체 - 값 타입 분류 - 기본값 타입(int, double, Integer, Long, String): 생명주기를 엔티티의 의존, 값 타입은 공유하면 X - 임베디드 타입(embedded type, 복합 값 타입) - 컬렉션 값 타입(collection value type)
임베디드 타입
- 임베디드 타입
- 새로운 값 타입을 직접 정의할 수 있음
- JPA는 임베디드 타입(embedded type)이라 함
- 주로 기본 값 타입을 모아서 만들어서 복합 값 타입이라고도 함
@Embeddable: 값 타입을 정의하는 곳에 표시@Embedded: 값 타입을 사용하는 곳에 표시- 기본 생성자 필수
- 재사용
- 높은 응집도
- 임베디드 타입을 포함한 모든 값 타입은, 값 타입을 소유한 엔티티에 생명주기를 의존함
- 임베디드 타입과 테이블 매핑
- 임베디드 타입은 엔티티의 값일 뿐이다.
- 임베디드 타입을 사용하기 전과 후에 매핑하는 테이블은 같다.
- 잘 설계한 ORM 애플리케이션은 매핑한 테이블의 수보다 클래스의 수가 더 많음
@AttributeOverride: 속성 재정의- 한 엔티티에서 같은 값 타입을 사용하면 컬럼명이 중복됨
@AttributeOverrides,@AttributeOverride를 사용해서 컬럼명 속성을 재정의
값 타입과 불변 객체
- 값 타입은 복잡한 객체 세상을 조금이라도 단순화하려고 만든 개념이다. 따라서 값 타입은 단순하고 안전하게 다룰 수 있어야 한다.
- 값 타입 공유 참조
- 임베디드 타입 같은 값 타입을 여러 엔티티에서 공유하면 위험함
- 임베디드 타입처럼 직접 정의한 값 타입은 자바의 기본 타입이 아니라 객체 타입이다.
- 객체 타입은 참조 값을 직접 대입하는 것을 막을 방법이 없다.
- 객체의 공유 참조는 피할 수 없다.
- 불변 객체
- 객체 타입을 수정할 수 없게 만들면 부작용을 원천 차단
- 값 타입은 불변 객체(immutable object)로 설계해야함
- 불변 객체: 생성 시점 이후 절대 값을 변경할 수 없는 객체
- 생성자로만 값을 설정하고 수정자(Setter)를 만들지 않으면 됨
값 타입의 비교
- 동일성(identity) 비교: 인스턴스의 참조 값을 비교,
==사용 - 동등성(equivalence) 비교: 인스턴스의 값을 비교,
equals()사용 - 값 타입의
equals()메소드를 적절하게 재정의(주로 모든 필드 사용)
값 타입 컬렉션(권장하지 않음)
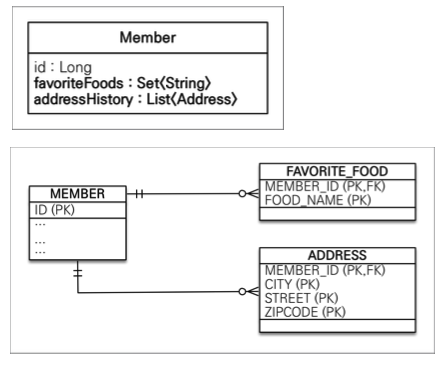
- 값 타입을 하나 이상 저장할 때 사용
@ElementCollection,@CollectionTable사용- 데이터베이스는 컬렉션을 같은 테이블에 저장할 수 없다.
- 컬렉션을 저장하기 위한 별도의 테이블이 필요함
- 값 타입 컬렉션도 지연 로딩 전략 사용
- 값 타입 수정시 필드 수정이 아닌 값 타입 단위로 교체해주어야 한다.(부작용 방지)
- 값 타입 컬렉션의 제약사항
- 값 타입은 엔티티와 다르게 식별자 개념이 없다.
- 값은 변경하면 추적이 어렵다.
- 값 타입 컬렉션에 변경 사항이 발생하면, 주인 엔티티와 연관된 모든 데이터를 삭제하고, 값 타입 컬렉션에 있는 현재 값을 모두 다시 저장한다.
- 값 타입 컬렉션을 매핑하는 테이블은 모든 컬럼을 묶어서 기본 키를 구성해야 함:
null입력X, 중복 저장X
- 값 타입 컬렉션 대안
- 값 타입 컬렉션 대신에 일대다 관계를 고려
- 일대다 관계를 위한 엔티티를 만들고, 여기에서 값 타입을 사용
- 영속성 전이(
Cascade) + 고아 객체 제거를 사용해서 값 타입 컬렉션 처럼 사용
–> 값 타입은 정말 값 타입이라 판단될 때만 사용, 엔티티와 값 타입을 혼동해서 엔티티를 값 타입으로 만들면 안됨, 식별자가 필요하고 지속해서 값을 추적 / 변경해야 한다면 그것은 값 타입이 아닌 엔티티
객체지향 쿼리 언어1 - 기본 문법
소개
- JPQL
- QueryDSL
-
네이티브 SQL
- JPQL
- 검색을 할 때도 테이블이 아닌 엔티티 객체를 대상으로 검색
- 애플리케이션이 필요한 데이터만 DB에서 불러오려면 결국 검색 조건이 포함된 SQL이 필요
- JPA는 SQL을 추상화한 JPQL이라는 객체 지향 쿼리 언어 제공
- JPQL은 엔티티 객체를 대상으로 쿼리
- SQL은 데이터베이스 테이블을 대상으로 쿼리
- SQL을 추상화해서 특정 데이터베이스 SQL에 의존X
- JPQL을 한마디로 정의하면 객체 지향 SQL
String jpql = "select m from Member m where m.age > 18";
List<Member> result = em.createQuery(jpql, Member.class).getResultList();
select
m.id as id,
m.age as age,
m.USERNAME as USERNAME,
m.TEAM_ID as TEAM_ID
from
Member m
where
m.age > 18
- queryDSL
- 문자가 아닌 자바코드로 JPQL을 작성할 수 있음
- JPQL 빌더 역할
- 컴파일 시점에 문법 오류를 찾을 수 있음
- 동적쿼리 작성 편리함
- 단순하고 쉬움
//JPQL
//select m from Member m where m.age > 18
JPAFactoryQuery query = new JPAQueryFactory(em);
QMember m = QMember.member;
List<Member> list =
query.selectFrom(m)
.where(m.age.gt(18))
.orderBy(m.name.desc())
.fetch();
- 네이티브 SQL
- JPA가 제공하는 SQL을 직접 사용하는 기능
- JPQL로 해결할 수 없는 특정 데이터베이스에 의존적인 기능
String sql = "SELECT ID, AGE, TEAM_ID, NAME FROM MEMBERWHERE NAME = ‘kim’";
List<Member> resultList = em.createNativeQuery(sql, Member.class).getResultList();
- JDBC 직접 사용, SpringJdbcTemplate 등
- JPA를 사용하면서 JDBC 커넥션을 직접 사용하거나, 스프링 JdbcTemplate, 마이바티스등을 함께 사용 가능
- 단 영속성 컨텍스트를 적절한 시점에 강제로 플러시 필요
- 예) JPA를 우회해서 SQL을 실행하기 직전에 영속성 컨텍스트 수동 플러시
기본 문법과 쿼리 API
select m from Member as m where m.age > 18
- 엔티티 이름 사용, 테이블 이름이 아님(Member)
- 별칭은 필수(m) (as는 생략가능)
- 집합과 정렬
select
COUNT(m), //회원수
SUM(m.age), //나이 합
AVG(m.age), //평균 나이
MAX(m.age), //최대 나이
MIN(m.age) //최소 나이
from Member m
- GROUP BY, HAVING, ORDER BY
- TypeQuery, Query
- TypeQuery: 반환 타입이 명확할 때 사용
- Query: 반환 타입이 명확하지 않을 때 사용
TypedQuery<Member> query = em.createQuery("SELECT m FROM Member m", Member.class);
Query query = em.createQuery("SELECT m.username, m.age from Member m");
- 결과 조회 API
- query.getResultList(): 결과가 하나 이상일 때, 리스트 반환, 결과가 없으면 빈 리스트 반환
- query.getSingleResult(): 결과가 정확히 하나, 단일 객체 반환
- 결과가 없으면:
javax.persistence.NoResultException - 둘 이상이면:
javax.persistence.NonUniqueResultException - 스프링 데이터 JPA 사용시
try ~ catch를 통해null이나Optional객체를 반환
- 결과가 없으면:
- 파라미터 바인딩 - 이름 기준
SELECT m FROM Member m where m.username=:username
query.setParameter("username", usernameParam);
프로젝션(SELECT)
- SELECT 절에 조회할 대상을 지정하는 것
- 프로젝션 대상: 엔티티, 임베디드 타입, 스칼라 타입(숫자, 문자등 기본 데이터 타입)
SELECT m FROM Member m-> 엔티티 프로젝션SELECT m.team FROM Member m-> 엔티티 프로젝션SELECT m.address FROM Member m-> 임베디드 타입 프로젝션SELECT m.username, m.age FROM Member m-> 스칼라 타입 프로젝션- DISTINCT로 중복 제거
- 프로젝션 - 여러 값 조회
- Query 타입으로 조회
- Object[] 타입으로 조회
- new 명령어로 조회
- 단순 값을 DTO로 바로 조회(
SELECT new jpabook.jpql.UserDTO(m.username, m.age) FROM Member m) - 패키지명을 포함한 전체 클래스명 입력
- 순서와 타입이 일치하는 생성자 필요
- 단순 값을 DTO로 바로 조회(
페이징 API
- JPA는 페이징을 다음 두 API로 추상화
setFirstResult(int startPosition): 조회 시작 위치(0부터 시작)setMaxResults(int maxResult): 조회할 데이터 수
String jpql = "select m from Member m order by m.name desc";
List<Member> resultList = em.createQuery(jpql, Member.class)
.setFirstResult(10)
.setMaxResults(20)
.getResultList();
조인
- 내부 조인:
SELECT m FROM Member m [INNER] JOIN m.team t - 외부 조인:
SELECT m FROM Member m LEFT [OUTER] JOIN m.team t - 세타 조인:
select count(m) from Member m, Team t where m.username = t.name - 조인 - ON 절
- 조인 대상 필터링( 예) 회원과 팀을 조인하면서, 팀 이름이 A인 팀만 조인 )
- 연관관계 없는 엔티티 외부 조인(하이버네이트 5.1부터)
서브 쿼리
- 나이가 평균보다 많은 회원
select m from Member m
where m.age > (select avg(m2.age) from Member m2)
- 한 건이라도 주문한 고객
select m from Member m
where (select count(o) from Order o where m = o.member) > 0
- 서브 쿼리 지원 함수
- [NOT] EXISTS (subquery): 서브쿼리에 결과가 존재하면 참
- ALL 모두 만족하면 참
- ANY, SOME: 같은 의미, 조건을 하나라도 만족하면 참
- [NOT] IN (subquery): 서브쿼리의 결과 중 하나라도 같은 것이 있으면 참
- JPA 서브 쿼리 한계
- JPA는 WHERE, HAVING 절에서만 서브 쿼리 사용 가능
- SELECT 절도 가능(하이버네이트에서 지원)
- FROM 절의 서브 쿼리는 현재 JPQL에서 불가능
조건식 - CASE 식
- 기본 CASE 식
select
case when m.age <= 10 then '학생요금'
when m.age >= 60 then '경로요금'
else '일반요금'
end
from Member m
- 단순 CASE 식
select
case t.name
when '팀A' then '인센티브110%'
when '팀B' then '인센티브120%'
else '인센티브105%'
end
from Team t
- COALESCE: 하나씩 조회해서 null이 아니면 반환
select coalesce(m.username,'이름 없는 회원') from Member m
- 사용자 이름이 ‘관리자’면 null을 반환하고 나머지는 본인의 이름을 반환
select NULLIF(m.username, '관리자') from Member m
JPQL 사용자 정의 함수
- 사용하는 DB 방언을 상속받고, 사용자 정의 함수를 등록한다.
- 하이버네이트는 사용전 방언에 추가해야 한다.
select function('group_concat', i.name) from Item i
객체지향 쿼리 언어2 - 중급 문법
경로 표현식
- .(점)을 찍어 객체 그래프를 탐색하는 것
select m.username -> 상태 필드
from Member m
join m.team t -> 단일 값 연관 필드
join m.orders o -> 컬렉션 값 연관 필드
where t.name = '팀A'
- 상태 필드(state field): 단순히 값을 저장하기 위한 필드 (ex: m.username)
- 연관 필드(association field): 연관관계를 위한 필드
- 단일 값 연관 필드:
@ManyToOne,@OneToOne, 대상이 엔티티(ex: m.team) - 컬렉션 값 연관 필드:
@OneToMany,@ManyToMany, 대상이 컬렉션(ex: m.orders)
- 단일 값 연관 필드:
- 상태 필드(state field): 경로 탐색의 끝, 탐색X
- 단일 값 연관 경로: 묵시적 내부 조인(inner join) 발생, 탐색O, 권장하지 않음
select o.member from Order o
select m.*
from Orders o
inner join Member m on o.member_id = m.id
- 컬렉션 값 연관 경로: 묵시적 내부 조인 발생, 탐색X, FROM 절에서 명시적 조인을 통해 별칭을 얻으면 별칭을 통해 탐색 가능
select m.username from Team t join t.members m
- 명시적 조인: join 키워드 직접 사용
select m from Member m join m.team t
- 묵시적 조인: 경로 표현식에 의해 묵시적으로 SQL 조인 발생 (내부 조인만 가능)
select m.team from Member m
- 실무 조언
- 가급적 묵시적 조인 대신에 명시적 조인 사용
- 조인은 SQL 튜닝에 중요 포인트
- 묵시적 조인은 조인이 일어나는 상황을 한눈에 파악하기 어려움
페치 조인 1 - 기본
- N + 1 문제는 즉시로딩이든 지연로딩이든 발생한다.
- SQL 조인 종류X
- JPQL에서 성능 최적화를 위해 제공하는 기능
- 연관된 엔티티나 컬렉션을 SQL 한 번에 함께 조회하는 기능
- join fetch 명령어 사용
- 엔티티 페치 조인
- 회원을 조회하면서 연관된 팀도 함께 조회(SQL 한 번에)
- JPQL:
select m from Member m join fetch m.team - SQL:
SELECT M.*, T.* FROM MEMBER M INNER JOIN TEAM T ON M.TEAM_ID=T.ID
- 컬렉션 페치 조인(일대다 관계)
select t
from Team t join fetch t.members
where t.name = ‘팀A'
SELECT T.*, M.*
FROM TEAM T
INNER JOIN MEMBER M ON T.ID=M.TEAM_ID
WHERE T.NAME = '팀A'

- 페치 조인과 DISTINCT
- SQL에 DISTINCT를 추가
- 애플리케이션에서 엔티티 중복 제거
select distinct t
from Team t join fetch t.members
where t.name = ‘팀A’
- SQL에
DISTINCT를 추가하지만 데이터가 다르므로 SQL 결과에서 중복제거 실패 DISTINCT가 추가로 애플리케이션에서 중복 제거시도- 같은 식별자를 가진 Team 엔티티 제거
- 페치 조인과 일반 조인의 차이
- 일반 조인 실행시 연관된 엔티티를 함께 조회하지 않음
- JPQL은 결과를 반환할 때 연관관계 고려X, 단지 SELECT 절에 지정한 엔티티만 조회할 뿐
- 페치 조인을 사용할 때만 연관된 엔티티도 함께 조회(즉시 로딩)
- 페치 조인은 객체 그래프를 SQL 한번에 조회하는 개념
페치 조인 2 - 한계
- 페치 조인 대상에는 별칭을 줄 수 없다.(하이버네이트는 가능, 가급적 사용X)
- 둘 이상의 컬렉션은 페치 조인 할 수 없다.
- 컬렉션을 페치 조인하면 페이징 API(
setFirstResult,setMaxResults)를 사용할 수 없다.- 일대일, 다대일 같은 단일 값 연관 필드들은 페치 조인해도 페이징 가능
- 하이버네이트는 경고 로그를 남기고 메모리에서 페이징(매우 위험) -> 데이터베이스에서 모든 데이터를 가져와서 객체 만든 후 애플리케이션에서 페이징 처리
@BatchSize: 일대다 조인에서 지연로딩시 IN 쿼리를 통해 한번에 연관 필드 객체를 가져와서 1 + N 문제를 1 + 1문제로 완화(글로벌 세팅도 가능)
엔티티 직접 사용
- JPQL에서 엔티티를 직접 사용하면 SQL에서 해당 엔티티의 기본 키 값을 사용
select count(m.id) from Member m //엔티티의 아이디를 사용
select count(m) from Member m //엔티티를 직접 사용
select count(m.id) as cnt from Member m
- 엔티티를 파라미터로 전달
String jpql = “select m from Member m where m = :member”;
List resultList = em.createQuery(jpql)
.setParameter("member", member)
.getResultList();
select m.* from Member m where m.id=?
Team team = em.find(Team.class, 1L);
String qlString = “select m from Member m where m.team = :team”;
List resultList = em.createQuery(qlString)
.setParameter("team", team)
.getResultList();
select m.* from Member m where m.team_id=?
벌크 연산
- JPA 변경 감지 기능으로 실행하려면 너무 많은 SQL 실행 -> 변경된 데이터가 100건이라면 100번의 UPDATE SQL 실행
- 쿼리 한 번으로 여러 테이블 로우 변경(엔티티)
String qlString = "update Product p " +
"set p.price = p.price * 1.1 " +
"where p.stockAmount < :stockAmount";
int resultCount = em.createQuery(qlString)
.setParameter("stockAmount", 10)
.executeUpdate();
executeUpdate()의 결과는 영향받은 엔티티 수 반환- UPDATE, DELETE 지원
- 벌크 연산은 영속성 컨텍스트를 무시하고 데이터베이스에 직접 쿼리(데이터베이스와 영속성 컨텍스트의 동기화 문제)
- 벌크 연산을 먼저 실행
- 벌크 연산 수행 후 영속성 컨텍스트 초기화
댓글남기기